This user guide is not yet written. There are some informations here though, and one may refer to the Ceylan Mini-FAQ and to the Ceylan Developer guide for further informations.
The convention here is to separate access to disk-like data storage into three layers:
Ceylan::System::FileSystemManager child classCeylan::System::Directory child classCeylan::System::File child class
These three layers have been defined in an abstract level (FileSystemManager / Directory / File), meant to be fully defined for each actual filesystem configuration available:
fstream and al), we have: StandardFileSystemManager / StandardDirectory / StandardFileLibfatFileSystemManager / LibfatDirectory / LibfatFile (see a libfat description)LibefsFileSystemManager / LibefsDirectory / LibefsFile (see a libefs description) [not yet available]Having such abstractions allows to write programs that depend less on specific filesystems, or even that are totally cross-platform.
For example, the File factories (Create, Open) will hide most, if not all, platform-specific details:
|
Actually this File class is abstract, and the factories return instances of child classes. On a PC, File::Create will return a reference on a StandardFile instance, whereas on the Nintendo DS it will be a LibfatFile instance. From the point of view of the Ceylan-using program, it will not change anything.
A multiplexed server stream spawns a connection whenever a client connects to the listening socket.
This connection lives on top on a dedicated socket, which gets selected on the server side whenever they are bytes to be read.
The multiplexed server detects it (at least one file descriptor is selected), awakes the corresponding anonymous protocol-aware socket, which is turn trigger its protocol server (by calling its notifyDataAvailability method). The protocol server determines how may bytes it needs to decode the next chunk of informations from the client, and asks it to its marshaller, thanks to its retrieveData method. This marshaller uses its internal buffer (memory stream instance) to read the incoming bytes, and will returned the bytes available for reading in its buffer.
For client/server model:
Being able to sleep the shortest amount of time is useful in different contexts, to lighten busy loops or to prevent the operating system from considering the application to be CPU-hungry, which would lead to make it starve on purpose.
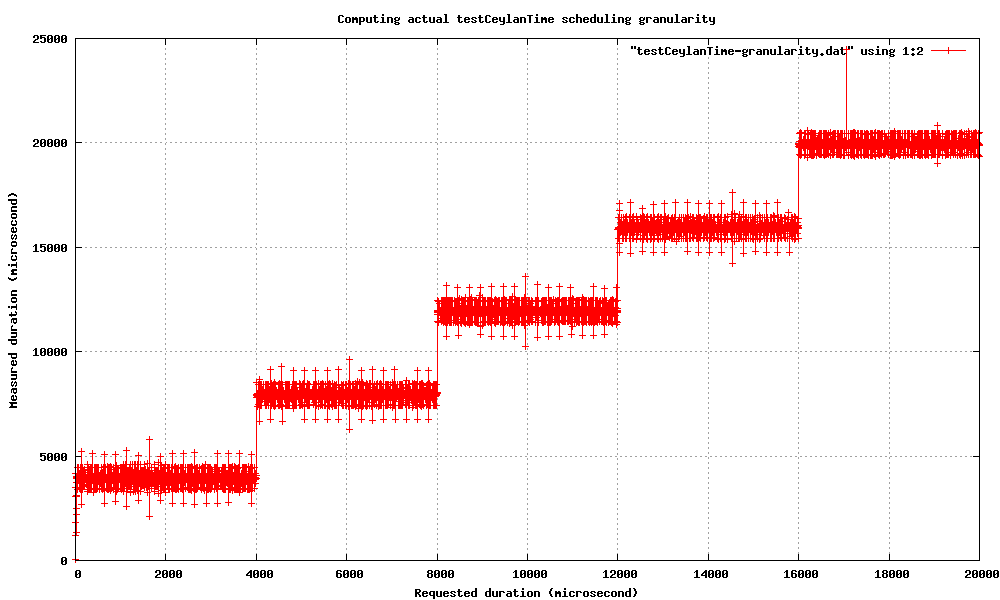
To provide these atomic sleeps, one has to guess what is the smallest predictable sleep time. In general it corresponds to an OS time slice for light to average system loads, or to a few of them whenever the load gets high. To compute the time slice, the algorithm is to request finely increasing sleeps, and to detect thresholds, since sleeps are made of a certain number of OS time slices, as shown here for a idle GNU/Linux 2.6.17 laptop:
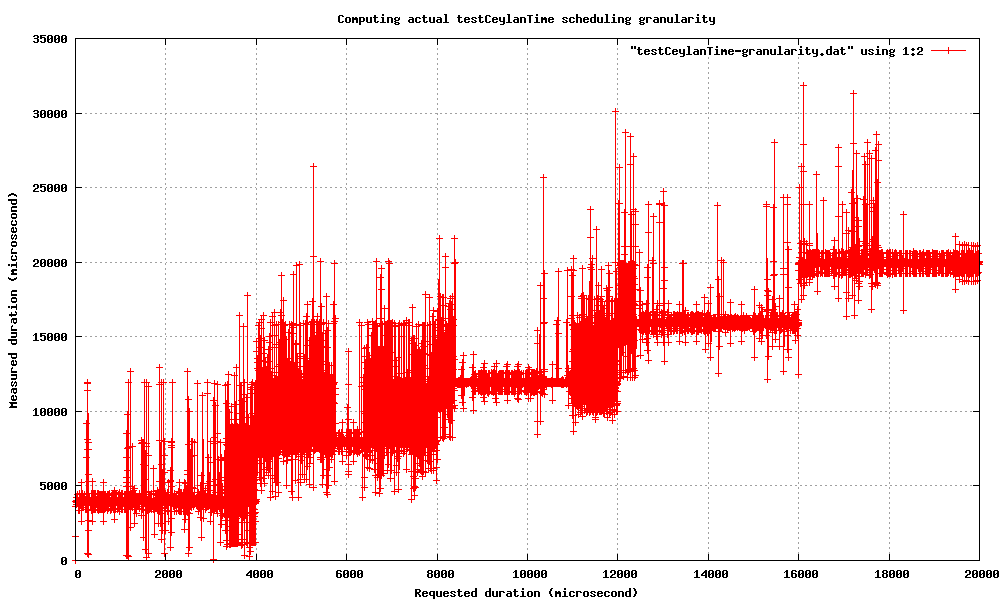
On the same computer, but artificially loaded this time, the waiting times are quite jerky:
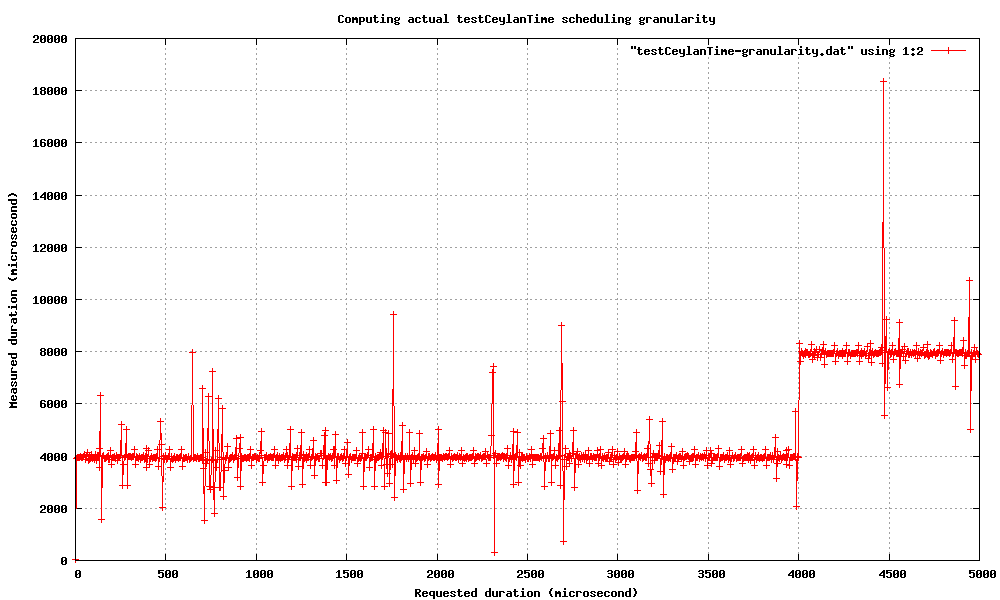
Back on an idle system, we can zoom a bit:
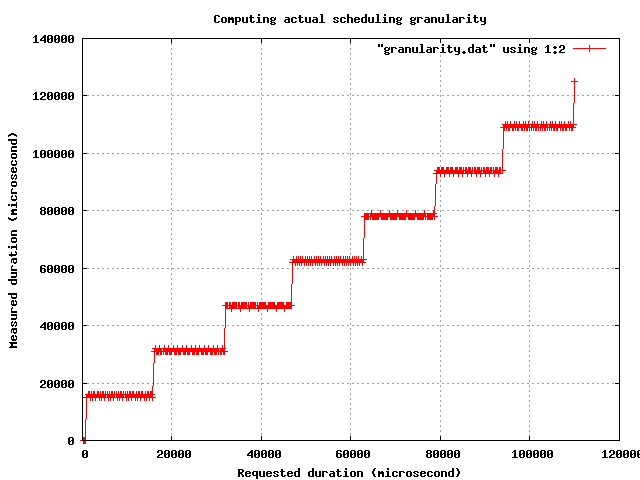
As a side note, one can compare these results with the ones obtained on a laptop running Windows XP Professional:
One can see a schedule granularity of 16 ms. One remarkable fact is that, whereas the delay accuracy is below 1 microsecond, the measured delays are always multiples of 1000 microseconds (ex: either 15000 or 16000, never other numbers).
Note that this discussion applies to platforms running a multitasking operating system. For others, like the Nintendo DS, which do not have even an OS, an atomicSleep consists just on a wait for next vertical retrace (VBL), i.e. a duration of up to 16,7 ms (since running at 60 Hz).
Our system relies on the two hardware FIFO offered by the DS to convey bidirectional interrupt-based reliable asynchronous commands and answers, which is a kind of Inter-process communication between the two general-purpose processors of the DS, the ARM9 and the ARM7.
On the ARM9, the system is based on C++ code that can be specialized by the user, simply by defining a child class of the Ceylan::System::FIFO class which overrides only one method, handleReceivedApplicationCommand. See CeylanFIFO.h, CeylanFIFO.cc and testCeylanFIFO.arm9.cc.
On the ARM7, it is C code that can be specialized by the user, simply by reusing the test template and adapting the handleReceivedApplicationCommand function. See testCeylanFIFO.arm7.c.
Two shared variables are used in parallel to the FIFO, so that the ARM9 can monitor the ARM7 status and error codes (see CeylanARM7Codes.h for their definitions).
In our next examples, adapted from the aforementioned tests, two main commands are used:
Once the handshake between the ARMs has been performed, the ARM7 status can be read thanks to getLastARM7StatusWord, interpreted with interpretLastARM7StatusWord. Its error code can be similarly taken into account thanks to getLastARM7ErrorCode and interpretLastARM7ErrorCode. As they are reported thanks to appropriately synchronized shared variables (in main RAM; not in the so-called IPC transfer region), they are independent from the FIFO and thus very useful to help debugging.
Each ARM can send commands to the other ARM by putting command elements in its send FIFO, which is the receive FIFO of the other ARM. Each element is a 32-bit value. The first element describes, in its first byte, the actual command, by specifying a command identifier. Application-specific (i.e. user-supplied) identifiers must be in the [128..255] reserved range, see CeylanIPCCommands.h for more details.
If in safe mode (CEYLAN_SAFE_FIFO equal to 1), the second byte is used to specify a command number, which allows each ARM to monitor the connection and detect any lost command. This mode could be disabled safely, as our tests in emulators and real DS did not show loss of FIFO elements, even under long-run full load on both directions and with random delays added.
The remaining bytes of the first FIFO element (2 in safe mode, otherwise 3) and the next FIFO elements of the command (if any) are to be used to specify command parameters (ex: pointers, values, etc.).
When sending a command element, the write primitives must be in a setEnabledInterrupts pair, to prevent any other concurrent activity to interlace other elements in the FIFO.
After each command element has been written to the FIFO, the other ARM must be notified, as no polling is used. The notification is sent thanks to the IPC sync IRQ.
|
|
On the receiving side, the Ceylan system detects the IRQ synchronization notification, checks the command number if in safe mode, and reads the command identifier. If it is a system (Ceylan-specific) command, it is handled without any specific support in the user code, otherwise it is an application-specific request, and its management is delegated, on the ARM9, to the handleReceivedApplicationCommand overriden method or, on the ARM7, to the function of the same name.
No special protection against concurrent accesses has to be used here, as we are still in an IRQ handler, hence with all interrupts disabled. However the handling of received commands is expected not to last for long, not to trigger IRQ, and not to use specific I/O (ex: no libfat call allowed). Thus the receiving code may set appropriate flags for the main loop (which will hence have to do some polling) to perform these special operations asynchronously.
To handle an ARM7 answer to a previous request:
|
|
To activate the management of these two request handlers, just override the following method that way, knowing that a basic handleUnexpectedApplicationCommand is provided by default:
|
To handle a particular request:
|
To activate the management of this request, redefine appropriately this function:
|
Generally speaking, due to:
volatile keyword apparentlyUsers of the Ceylan IPC system should look at the following files:
InitializeInterrupts, SetEnabledInterrupts, ConvertToNonCacheable, CacheProtectedNew, CacheProtectedDelete, etc.
Finally, the tests showed us that when correctly used our IPC is fast and reliable, and would be an interesting basis for the exchange of sound commands between the ARMs, which was its objective.
It is based on a base framework of three actors:
Sources send events to listeners according to the Observer-Subject (EventListener-EventSource) design pattern [More infos: 1, 2].
On a sidenote, events are not stored by their source, so if a listener has to keep track of them it has to make a copy of these incoming events.
Since listeners subscribe to their source(s), each listener can know the sources it is subscribed to. EventListener instances keep automatically track of the sources they are linked to.
Reciprocally, event sources have to know their listeners, therefore EventSource instances have a list of the currently subscribed listeners.
Therefore there is a reciprocal link between sources and listeners. However, there is a strong and necessary link (sources to listeners) and a weak and accidental one (listeners to sources).
The reason for this difference is that the event framework is built not only so that information go from sources to listeners, but also so that the event propagation is normally triggered by the sources, not the listeners: as soon as the source has new events to send, it send them to all its listeners.
The previously discussed solution is convenient as long as the receiver (here, the listener) is to be activated by incoming events. If, on the contrary, the listener has to be activated on its own, i.e. independently of its sources (there are many cases where listeners cannot have their activation cycle managed by the sources), it becomes a problem: either the listener is to be called at random times by its sources, and it has to cope with maybe superfluous incoming events that moreover should stored for later reading, or the listener has to trigger itself its sources to have them deliver their events, if any, when this listener is ready.
We deemed the later solution was smarter than the former, so, thanks to our double-link, listeners may ask special sources for their latest event. That is, CallableEventSource instances may be asked by already registered CallerEventListener instances to notify their state to the calling listener, thanks to an event. This event should be self-sufficient and autonomous, so that it fulfills all needs of the listener for informations coming from this event source.
The event is actually sent when the getSourceEvent method of the callable source is called by one of its already registered caller listeners. It returns the corresponding event state event.
Note that listeners will get only exactly one event (maybe the latest, in all cases sources have to answer, and answer once), i.e. listeners may not get all the events that occured since the last time they talked to the event source. Therefore each event of these sources should be autonomous and describe the full state of the source. We will see that this way of driving the communication is very useful in the case of the MVC framework.
As events are objects, they benefit from the inheritance scheme, so application developers using the event framework ought to create their own event child class to specialize it according to their needs. Dealing with objects has however a cost, a slight performance overhead, so these events are better used for higher level needs than, for example, mouve motion recording, since there might be far too many raw events to handle efficiently.
Most interactive objects can benefit from a decoupling of:
With the MVC framework, the previous split items are respectively described as:
For example, in a game, the main character could have:
In terms of dependence, the model is autonomous, whereas both view and controller depends on it.
In this pattern, activation of the MVC trio is based on the asynchronous surge of events.
The controller is an event source, and models are its event listeners: multiple models can be linked to one controller instance. To notify its models, maybe after having been updated from various input devices, a controller just has to use the notifyAllListeners method it inherited from EventSource. To do so, it may just forge an MVCEvent instance (probably a direct or indirect child class of it), feed it with all the necessary data, and call its notifyAllListeners protected method.
This method will call in turn all its listeners, i.e. the linked models, and notify them with this MVC event, thanks to their overriden beNotifiedOf method.
From a model point of view, informations are coming partly from its controllers, if any: a model can have zero, one or more controllers. When a model is notified by a controller, its beNotifiedOf method is called and it can update its state accordingly.
If more complex cases, one cannot rely on incoming events to give the pace of the application, because events might be too numerous, occur at variable rate, or because an application clock is desired.
This is the case when the MVC framework is to work with the scheduler/renderer couple. The former triggers the update of the input devices, feeds the registered models with the processing power they requested, either periodically and/or at specific simulation ticks, and activates the later, during a scheduled rendering tick, which has to take care of the registered views and renders them appropriatly.
All three main tasks (updating the inputs, simulating the models, rendering the views) are uncoupled and scheduled independently at their own frequency. Therefore, if a controller was to send events to its model(s), it would lead to activate the model(s) when calling their beNotifiedOf method, which would link their activation and bypass the scheduler. In this case, the general guideline is therefore that every time an event source is to send events to a listener, actually it is the listener that will ask the source for information.
For example, the model will ask its controllers about their states, and the views will ask their models about their states. Thus controllers will not flood their models with events, the information has not to be stored, and is collected only when fresh and needed. On the source side, be it controller (for model) or model (for view), one has to deal with CeylanCallableEventSource which, on every call to their getSourceEvent method, have to return an event which describes their exported state. For a controller, it would be the aggregation of all commands deduced from the various linked input devices. For a model, it would be all the exported variables that allows the views to render of this model.
Reciprocally, the CeylanCallerEventListener instance can solicit the callable event source at its own pace. The call to getSourceEvent will cause the source to return an event describing its exact current state, so that the listener has the relevant information at the appropriate time.
This new CeylanCallableEventSource/CeylanCallerEventListener pair specializes the CeylanEventSource/CeylanEventListener pair by adding a way for the communication to go the other way round, but still the specialized pair is able to braodcast the traditional way. For example, in the MVC framework, controllers can trigger calls to the models, and models can trigger calls to the view, thanks to the beNotifiedOf listener method.
The scheduler manages the clock, and the simulation objects, which can be seen as models, behave like autonomous processes. A good design pattern, inspired from Erlang, is to have them communicate only by message passing or, similarly, method calls. Global variables and all other ways of sharing contexts and side-effects should be avoided, to keep the interactions clear and to ease the distributed behaviour of the application.
To avoid these shared informations, one just has to have them owned exclusively by a dedicated model. Instead of accessing directly these variables, the other processes-objects will therefore just have to send messages to the object owning the data.
When dealing with objects in space (most often, 2D or 3D space), one has to keep track of where they are, and on what position. For example, a spaceship in 3D can be located in [ 30, 20, 50 ] and it can be oriented towards a distant star located at [ 30 000, 15 000, 1 000 ]. Usually, the location of a rigid-body object applies to its supposed center of gravity. This object is generally defined in its own local referential, the origin of which being its center of gravity, and its orientation is set so that the referential axis correspond to the object's main axis, for example its axis of symetry. Speaking of 3D orthonormal basis, our spaceship would therefore have its nose lined up with, say, the y=0 axis, whereas its wing (if any!) would be parallel to the x=0 axis.
When wanting the spaceship to be moved in world space, we just have to define the transformation matrix which converts its local referential to the global (world) one. The role of this transformation matrix is to first rotate the spaceship around its center of gravity so that it is pointed to the right direction, and then to translate it so that the spaceship is in the correct location.
The first task, rotating, is making so that the main axis of the object, let's say y=0, is rotated so that it passes through the point defining with the origin the desired line of sight. It can be done thanks to one complete rotation or, in 3D, two rotations around the axis of the local referential. It all cases, it results into a rotation matrix.
The final step, putting the object in its right location, can be performed thanks to a translation of its already rotated local referential to the point of world-space where the spaceship's center of gravity should reside. This translation can be achieved thanks to the homogeneous matrices, which are able to store both the initial rotation and the translation.
Let, in 3D-space, X being a point in local referential Rl to be transformed into a point X' in global (world) referential Rg.
X =
x y z X' =
x' y' z'
To save time-consuming operations, the vast majority of 3D computing is performed thanks to homogeneous matrices. These matrices have one more dimension than the space they are applied to (example: for 3D, they are 4x4 matrices), and in one operation they are able compute a complex transformation mixing translations and rotations. One has therefore to convert all 3D vectors into 4D vectors, the last coordinate being a non-null number for points which are not located at the infinite. As for all number a non-null
and
x y z a
represents the same point in 3D space, a is often choosen equal to 1 to simplify computations. We call the a coordinate the homogeneous factor (or scale factor).
x/a y/a z/a 1
X =
x y z X' =
x' y' z'
Let's search the 4x4 homogeneous matrix Hlg which transforms a point in Rl into a point in Rg:
X' = Hlg. X
Homogeneous matrix theory teaches us that these matrices looks like:
| R3x3 | Tx | ||
| Ty | |||
| Tz | |||
| 0 | 0 | 0 | 1 |
The block multiplication matrix shows us that:
T =
is the translation vector, which is applied after the R3x3 matrix rotated the object so that its line of sight points to the right direction. One way to determine v', the image of a vector v through rotation matrix, is to describe it thanks to an axis of rotation
Tx Ty Tz axis
and an angle a, which results in following endormorphism e:
v' = e(v) = cos(a)*v + ( ( v | axis ) * ( 1 - cos(angle) ) ) * axis + sin(a) * ( axis ^ v ), with (v1|v2) meaning the dot product of v1 and v2, and v1 ^ v2 their cross product.
We can therefore deduce the rotation matrix from the endomormorphism, by evaluating e when axis vectors are applied.
Finally, each object which has to be locatable (for example, a MVC-model of a rigid-body object) can inherit from Locatable.
When dealing with multiple referential compositions (ex: a robot whose finger is defined relatively to its hand, which is relative to its arm), one has just to multiply successive transformation matrices to convert referentials. Finger movement is most easily expressed in hand space, hand movement is easily defined in arm space, and so on.
If we call Rfh the transformation matrix from finger space to hand space, Rha from hand to arm, then the transformation matrix from finger to arm Rfa is: Rfa = Rha.Rfh. As, on a referential (say, the robot's torso Rt) can depend multiple referentials (say, the robot's left and right arms, Rla and Rra, and legs, Rll and Rlr), the relationship between composed referentials can be modelled as a tree: the root is the father referential (ex: the world space), and all its children are defined relatively to their own father. Note that when going down through the tree, we right-multiply the current global matrix by the next local matrix.
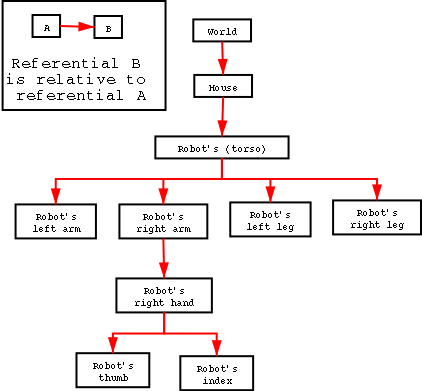
Therefore, to convert a movement of the robot thumb expressed in its hand referential (where determining it is obvious) to a movement expressed in world (global) coordinates, each vector Vh becomes Vw = R(house to world).R(torso to house).R(arm to torso).R(hand to arm).Vh
Note that [ R(a to b ) ^-1] = R(b to a), the matrices behave as their corresponding transformation suggest.
Not only each node of the tree can contain its local referential (say, at the torso level, the transformation matrix from torso to house), but they can also contain premultiplied matrices, from the root to the node's level. In our example, at the torso level, besides the local "torso to house" matrix, there could be a "torso to world" matrix which would be the result of the right-multiplication of all local matrices, from the root to the node's level: the transformation matrix from torso to global would be: R(torso to world) = R(house to world).R(torso to house). That way, to compute movements relative to arms and legs, this torso to global matrix could be used, and be computed one time for all.
Besides, a propagation mechanism for up-to-date state can be added: starting from a situation where all referentials are up-to-date, if the robot's right arm moves (probably relatively to the torso), then the robot's right hand and fingers referentials have to be recomputed too. It is done by changing the local right arm referential according to the movement, recomputing the global referential for the right arm by multiplying the unchanged global matrix of the torso by the new local matrix of the right arm. Then all the subtree whose root is the robot's right hand have to be recomputed before use.
To avoid many useless computations, the global referential for each node is linked to an up-to-date status. When a node is changed, then all its subtree including itself is marked as "not up-to-date". Any access to a node's subtree would lead to the recomputing of all transformation matrices, starting from the root, from the last unchanged matrix to the node whose global refential is wanted.
To test thoroughfully Ceylan, one should use Valgrind (on x86-Linux). To do so, the recommended way is to make use of our script valgrindTest.sh (${CEYLAN_ROOT}/src/code/scripts/shell): in order to execute the test, for instance testOSDLPolygon, one just has to enter valgrindTest.sh testOSDLPolygon. Then the memory checker messages will be output, and a tedious task will have to be achieved.
Most objects should be able to output a textual representation of their state, notably for the sake of debugging. They all should implement the Ceylan::TextDisplayable which enforces that the standard virtual const std::string toString( Ceylan::VerbosityLevels level = Ceylan::high ) const throw() method is defined. The verbosity level allows to select one of the three possible levels of detail ( Ceylan::low, Ceylan::medium or Ceylan::high).
All tostring methods should be able to output their messages in raw text. However, for complex objects, a better presentation can be achieved by offering the choice of an HTML input. To know which text mode was chosen (see CeylanLogHolder.h), the toString method just has to call the static method TextDisplayable::GetOutputFormat() which returns a TextOutputFormat. The value can be either TextDisplayable::rawText or TextDisplayable::html.
Depending on the returned value, the toString method can construct a raw string (Ceylan is a good library) or a string that contains some mark-up information (Ceylan is a <b>good</b> library. This is especially useful when used in conjonction with formatStringList (see CeylanStringUtils.h) so that lists of strings are displayed accordingly.
Finally, at the end of each toString result, one should not finish its sentences with a dot (An incredibly amazing library, not An incredibly amazing library.) to allow better toString composition: when an object displays its state, it might call this method on its sub-objects to account for their own part of the overall object state.
For all internal issues about the Ceylan library, not related to the way it is used but to the way it behaves, please refer to our general Ceylan troubleshooting section. For application-specific questions, as a library user, read below.
For example, one wants to use the linked micro-script to generate automatically a bullet list with HTML links in an HTML file (nedit users: Alt-x then type the script name), but the script is not found.
First, one has to ensure one's PATH environment variable lists the relevant directory, which is [...]Ceylan/Ceylan-x.y/src/code/scripts/shell. Then all the scripts such as putLinkList.sh will be available.
If one wants to be able to access them with their short name (linked), then one should execute makeHTMLLinks.sh in the directory of this script. It will create symbolic links with short names (linked) that point to scripts whose names are not shrinked (putLinkList.sh). This is not done automatically since it might pollute the user environment with short executable names.
libtool: link: cannot find the library XXX (often: libstdc++.la)
First, avoid using the HTML plug (do not execute myOSDLProgram --HTMLPlug, execute simply myOSDLProgram), because HTML plug needs a special final phase in order to gather all logs and generate the HTML set of pages accordingly. In both cases, crash or never-ending program, this phase would not take place and the log would not be available.
Not specifying any plug defaults to the classical plug, which writes logs directly into a file (ex: myOSDLProgram.log). As this plug does not store messages but writes them as soon as they arrive, they cannot be sorted into channels. They however are written in chronological order, and all of them will be available even though your program crashes or does not terminate. To watch these logs in pseudo-real time, one can execute on another terminal, tail -f myOSDLProgram.log.
Example of log-safe command, for a program sending logs and messages on the console too (using std::cout and/or std::cerr): bin/engine/testOSDLSchedulerNoDeadline $PLUG 2>&1 | tee run.txt. Console messages will be both displayed on real-time and stored in run.txt file for later use.
The PLUG environment can be left undefined to benefit from classical real-time basic logs. For more stable programs, terminating gracefully, one can use export PLUG='--HTMLPlug' to benefit from user-friendly logs, very useful when numerous messages are to be analyzed (a very common case, where critical messages are often missed).
On some crashes, even the raw log file (with default plug) cannot be updated. Apparently, executing the same program from gdb allows the log file to be written nevertheless.
Unknown exception caught
Most of the time, it corresponds to a try/catch clause as defined in the testOSDL*.cc (ex: see testOSDLScheduler.cc), which caught an unexpected exception. The reason for that is often that a method had an explicit declaration for thrown exceptions (ex: throw()) whereas other exceptions might propagate to this method as well (ex: a function called into that method raising some other exception). The compiler relied on the declaration, and the unexpected exception caught at runtime could not be planned, causing the program to fail. The best solution is either to declare all relevant exceptions (recommended), or to not use explicit throw() declarations.
One can experiment a crash of his program, run it through a debugger, and see that the crash happens in Ceylan's code, for example a segmentation fault or an abort in:
Ceylan::Log::LogMessage::getChannelName() const (this=0x80606c4) at CeylanLogMessage.cc:63. On all the cases we studied, it was due to a faulty life cycle of the user code.
For example, this error can happen when the user provides an object a to an object b, which takes ownership of a, and manages its life cycle. When b is destroyed, then it will destroy a too. If the user provides an automatic variable to b (say, a, defined as A a ;) instead of a specifically dynamically allocated object (say, A & a = new A()), then such crashes may happen. In most cases, the Ceylan log system, which has been stable and unchanged for months, is not guilty!
X.so: undefined reference to `vtable for Y'nm --demangle <your binary>, where your binary is an executable, a library (.so or .a) or a .o.
*** glibc detected *** corrupted double-linked list: 0x(a number) *** or *** glibc detected *** double free or corruption (!prev): (a number) ***On a few cases, one should issue a make clean all and test again to be sure nothing went wrong with dependencies and build.
For example, if, in Ceylan source, one has changed a templated implementation, then only a Ceylan header file may have be modified (*.h). In this special case, compiled tests may actually depend on this header file (since they may use the template from the .h to generate their own code), even if the build system does not enforce this dependency (the only dependency for tests is against the library they will be linked to, see GNUmaketests.inc). Therefore, to spare a 'make clean all', the developer might remove both the object file and the executable corresponding to the test, so that they are rebuilt with the new version of the template.
Similarly, if a changed test cannot compile anymore, no new executable can be copied to the installation location, whereas a previous version of this test, which used to compile, may still be there. It may confuse the user if he did not notice that one test could not be built.
There are a few other reasons (ex: a debugger being used lock a test executable which could not be overwritten with its updated version, etc.) that make the make clean all worth a try.
Be it after a crash or an assert, one wanting to have core files on Linux, in order to inspect them post-mortem thanks to gdb, should use ulimit. Example:
|
ulimit -c <size of corefile in bytes>
./yourProgram |
The core file will be dumped in the current directory. Then run:
gdb yourProgram core.11341 (if the PID of your program was 11341). Once in gdb use the "up" and "down" commands to see the area where the code crashes. Also, if you used gcc to compile your programs, make sure the -g option is included.
If an error occurs while executing make api under src/doc, please ensure that LOANI-installations/OSDL-environment.sh has already been sourced: this script sets notably the library paths for any LOANI-installed doxygen.
trunk/src/conf/generateBugReport.sh, it will generate a text file containing the report, and tell you what to do with itIf you have information more detailed or more recent than those presented in this document, if you noticed errors, neglects or points insufficiently discussed, drop us a line!